
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- spring boot
- java병렬처리
- 유스콘
- mustache함수
- 개발컨퍼런스
- 자바디자인패턴
- 스프링부트 프로젝트 이름 변경
- @advice
- 인텔리제이에서 프로젝트 이름 바꾸기
- 헥사고날
- js숫자체크
- MajorGC
- 클린아키텍처
- 동시요청
- 어댑터패턴
- reflection api
- 윈도우11 icloud 메모
- MinorGC
- Java
- test double
- 멀티코어 프로그래밍
- 테스트대역
- MappingJackson2HttpMessageConverter
- Spring
- 테스트더블
- refelction API
- java 멀티스레딩
- GOF
- 윈도우11 아이폰 메모 앱
- 윈도우11 바로가기
- Today
- Total
져니의 개발 정원 가꾸기
(java/spring) 병렬 프로그래밍 - 동시에 일을 처리하는 방법들 본문
목차

배경
최근 특정 데이터 수집하는 배치를 개발할 기회가 있었다. 외부 연동사로부터 데이터를 얻어와 데이터 후처리 및 DB에 적재하는 배치작업이었고, 처리 대상 데이터들이 많을 경우 배치의 수행속도를 높이기 위해 어떻게 배치 로직을 가져갈 것인가를 고민했다.
특히 [후처리 ~ DB적재 부분]을 배치 프로젝트 내부에서 다룰 것인지 마이크로서비스 API 서버에서 기능을 제공하도록 개발할 것인지가 메인 고민이었는데, 두 프로젝트 중 하나는 Java7이고, 하나는 Java8+ 이어서 어느 서버에서 제공할 것인지에 따라 적용 가능한 병렬 프로그래밍이 달라졌다.
실제로 수집되는 데이터를 확인해보니 수행시간이 과도하게 길어질 정도로 데이터가 많지 않아서 순차처리하기로 결정했지만, 트래픽이나 데이터 양이 많아질 경우 병렬처리가 성능 향상을 이끌어 낼 수 있기 때문에 학습한 주요 내용들을 정리한다.
Java8 이전
Javd8 이전의 병렬프로그래밍은 다시 Java5 이전과 이후로 나뉜다.
Java5 이전에는 Runnable과 Thread 클래스를 개발자가 직접 사용했다. Thread의 start() 메서드를 호출하여 실행할 작업(태스크)을 코드를 넘겨주는 것(제출)과 동시에 스레드를 실행했다.
Java5 부터는 스레드 풀을 통해 스레드를 생성하고 관리할 수 있는 기능이 추가 되었는데, ExecutorService클래스를 통해 스레드 풀을 이용할 수 있다.
ExecutorService
ExecutorSerivce에서 달라지는 점은 태스크 제출과 스레드 실행이 분리된다는 점이다.
- 작업을 제출하는 역할 (Submitting Tasks): 개발자가 ExecutorService에 작업을 제출
- 작업을 실행하는 역할 (Executing Tasks): ExecutorService가 작업을 스레드 풀에서 실행
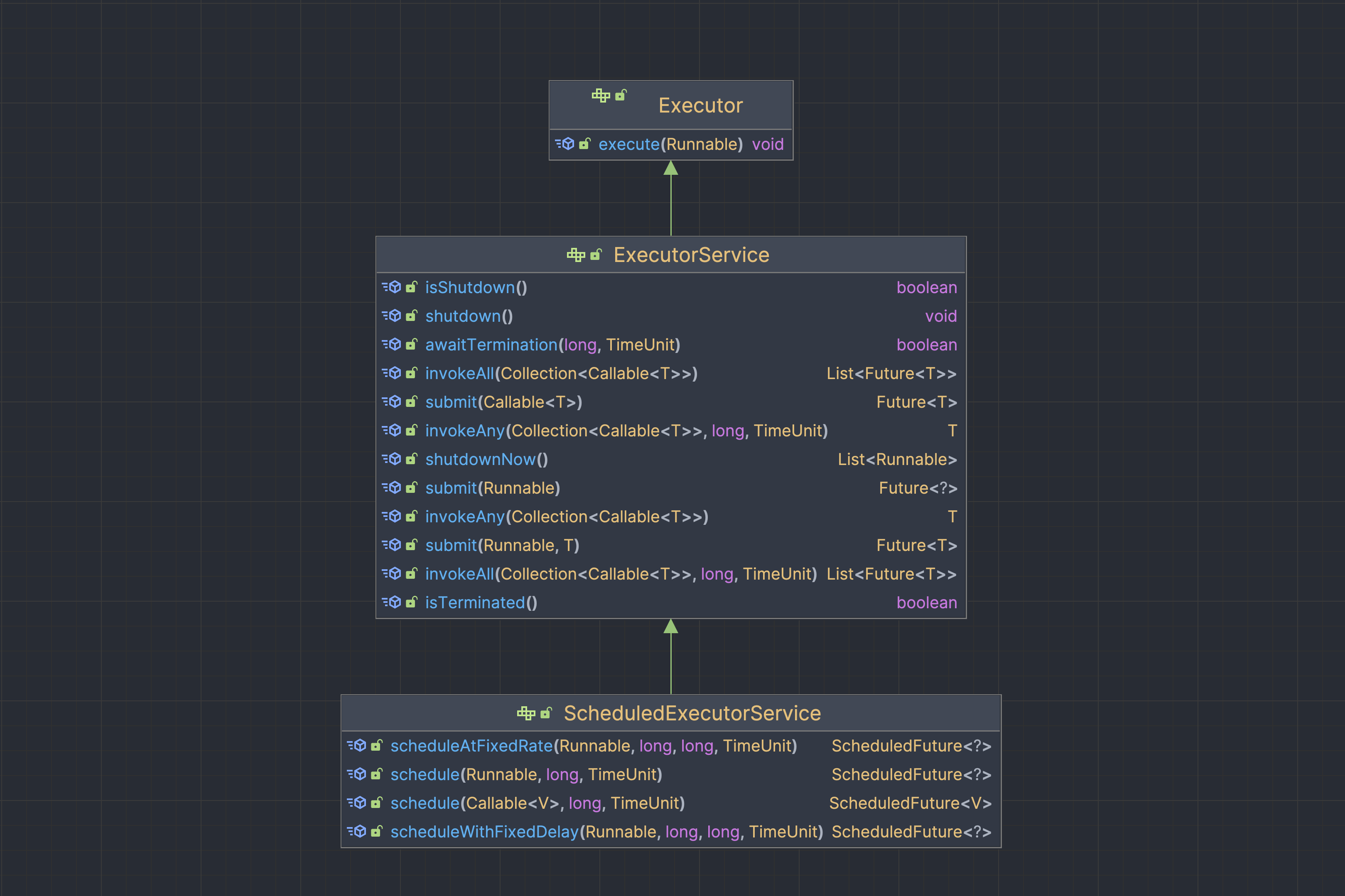
ExecutorService인터페이스의 시그니처를 보면 Executor 인터페이스를 확장한다. 실제 코드에서 메서드를 설명하는 부분을 보면ExecutorService.submit()이 작업을 제출하는 책임을, 상위 인터페이스인 Executor.execute()가 작업을 실행하는 책임을 가지는 것으로 각각 역할이 분리되었다. ExecutorService가 등장하기 이전에는 execute()로 개발자가 스레드를 직접 생성하고 실행 메서드를 호출했지만, 이제는 ExecutorService.submit()으로 실행할 작업만 제출하고 ExecutorService의 구현체에 따라 스레드풀에서 작업을 실행되는 것이다.

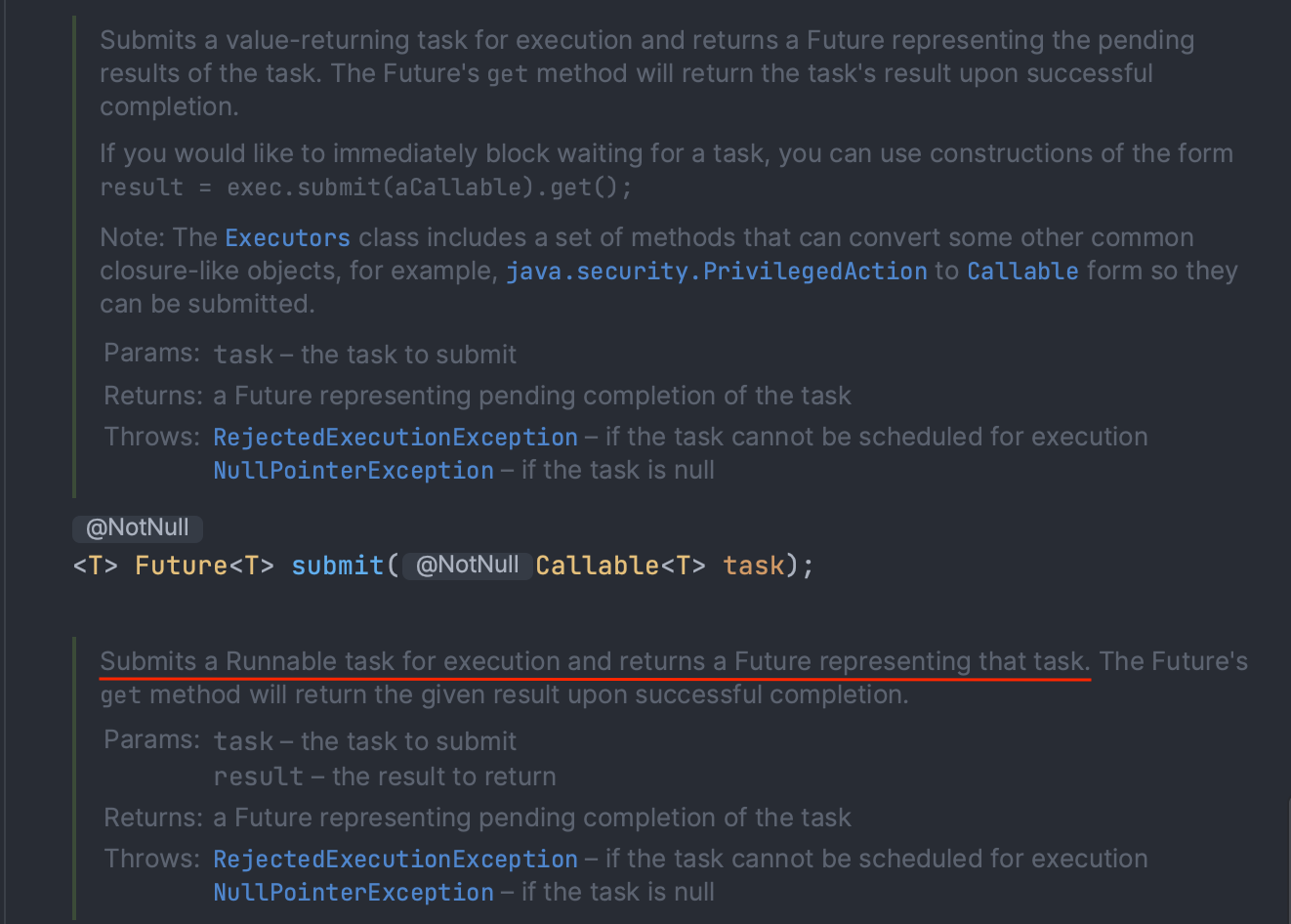
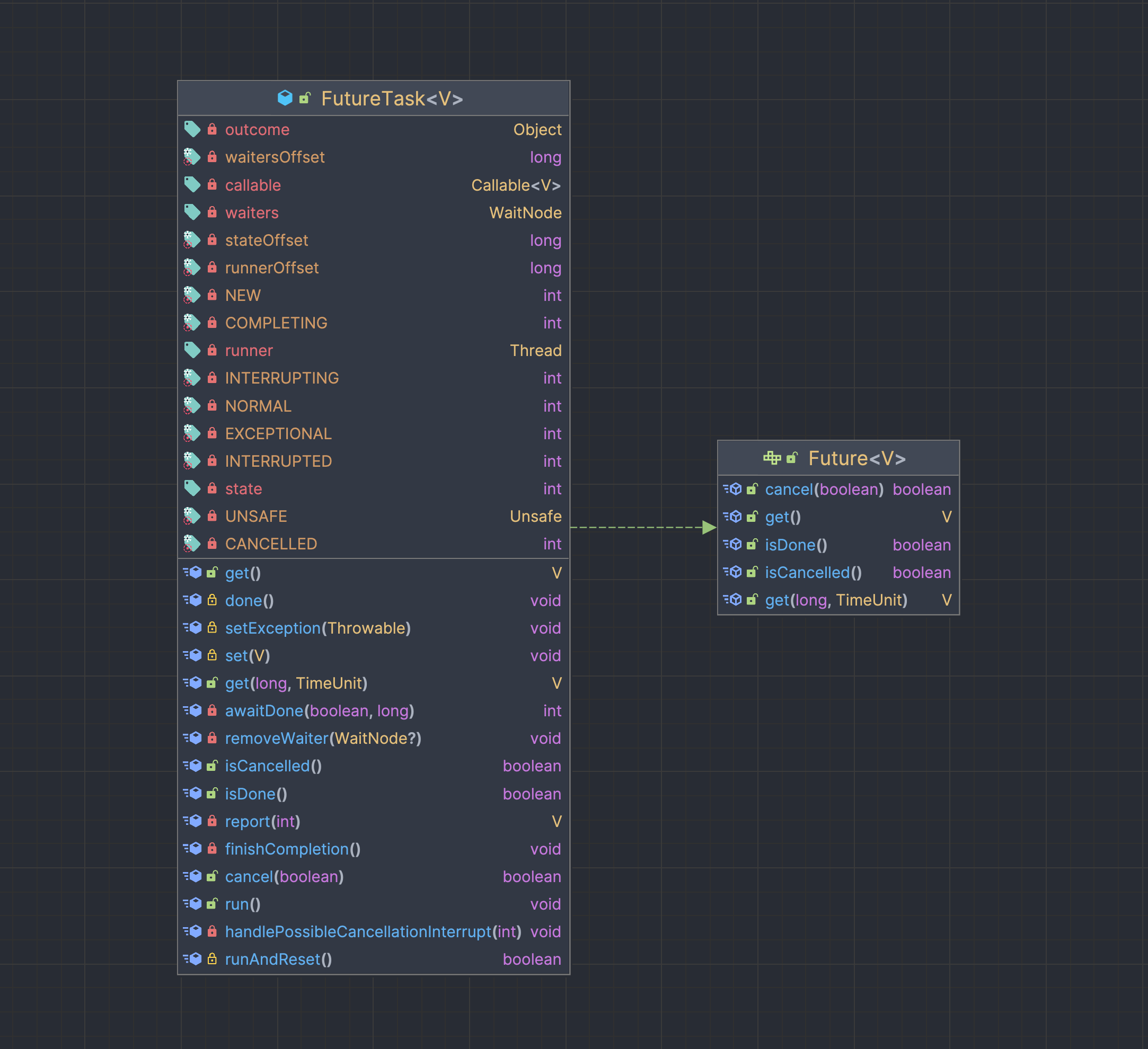
Future
ExecutorService의 submit()메서드는 실행할 작업을 Callable타입으로 받아 Future인터페이스의 구현체인 FutureTask타입의 객체를 반환한다. Future는 비동기 연산의 결과를 표현하는 인터페이스로, 실행할 작업의 결과에 접근할 수 있게 한다. submit()으로 제출한 작업은 쓰레드풀에서 관리되기 때문에 언제 실행이 될지 끝날지를 알 수 없는데, 인자로 넘긴 비동기 작업에 대한 Future라는 객체를 만들어 미래에 완료될 결과에 접근할 수 있게 한다.
이렇게 submit()으로 작업을 제출해 Future객체를 생성하면 해당 작업의 결과가 나올 때까지 기다리지 않고 다른 작업을 처리할 수 있다는 장점이 있다. 작업의 결과가 필요한 시점에서 Future.get()메서드를 호출하여 작업의 결과를 가져오면 되고, 추가적으로 선언되어있는isDone(), isCancelled()등의 메서드를 활용하여 흐름 또한 제어할 수도 있다.
주의할 것은, get()을 호출한 시점에 아직도 작업이 끝나지 않았을 경우 호출한 곳의 스레드를 블로킹하여 하염없이 기다리는 상태가 된다는 것이다. 이에 파라미터 2개로 선언된 get()오버로딩 함수를 사용하면 기다리는 시간을 지정하여 무한정 대기하는 것을 방지할 수 있다.
ex) get(2, TimgeUnit.SECOND); <- 2초의 timeout
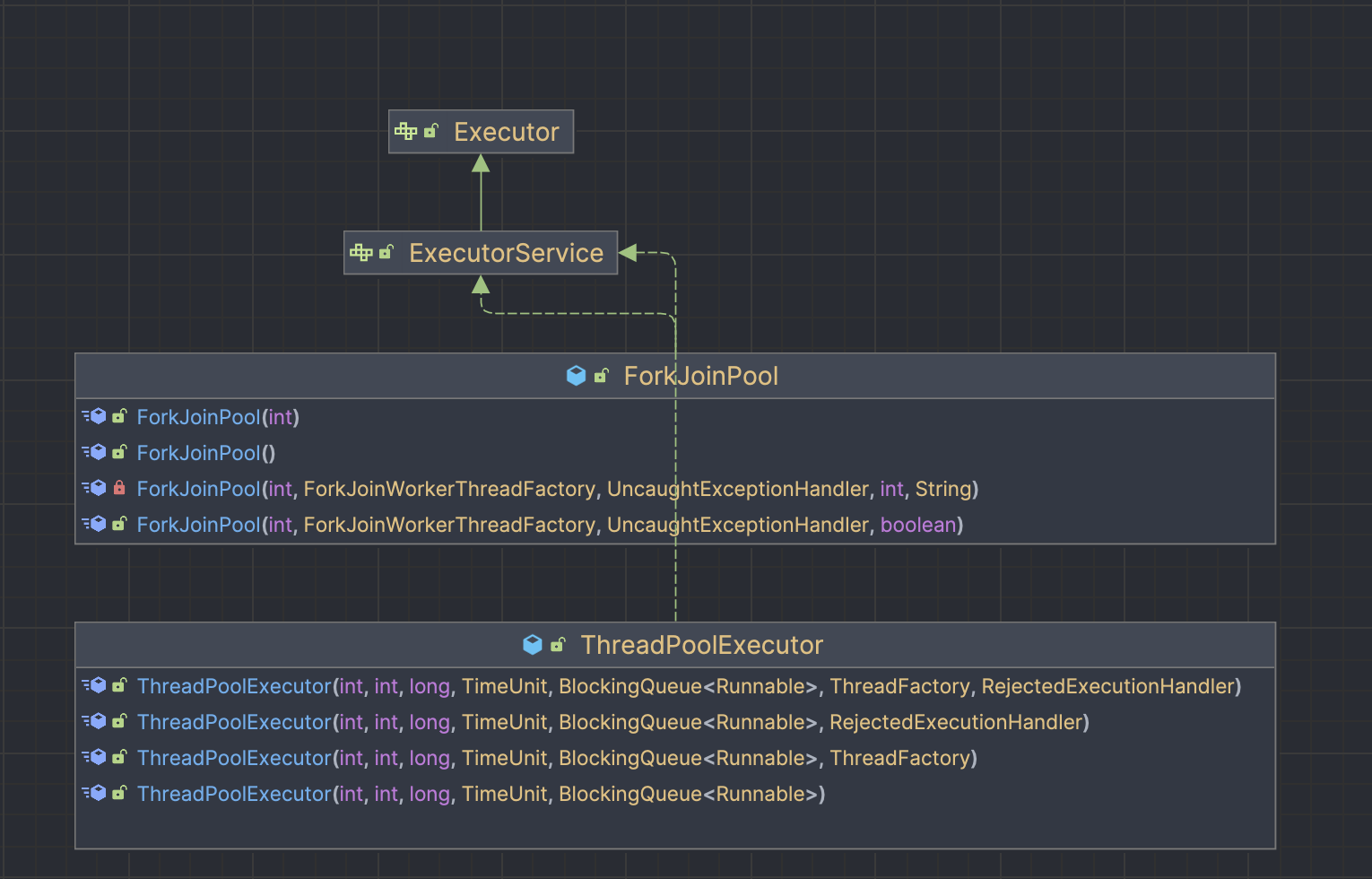
ExecutorService 구현체와 Executors
그러면 ExecutorService의 구현체는 뭐가 있을까? 대표적으로는 ThreadPoolExecutor와 ForkJoinPool이 있다. 그런데 해당 구현 객체들을 생성할 때 꽤나 많은 정보를 설정해줘야한다. 이에 Executors 팩토리 클래스(ExecutorService, ScheduledExecutorService등의 구현체를 생성)를 사용하면 일반적으로 유용하게 사용되는 쓰레드 풀 구성으로 설정할 수 있다.
(참고로, ScheduledExecutorService 까지 다루면 너무 블로그 글이 길어질 것 같아서 이제부터는 ExecutorService만 다룬다..ㅋ)

여기서 자주 사용되는 리턴타입이 ExecutorService인 팩토리 메서드 몇 가지이다.
- newFixedThreadPool
- 고정된 개수의 쓰레드를 생성하여 재사용하는 쓰레드 풀을 생성한다.
- 쓰레드들은 서로 공유하고 있는 무제한 크기의 작업 큐에서 동작한다.
- newCachedThredPool
- 필요한 만큼의 쓰레드를 생성하는 쓰레드 풀을 생성한다.
- 단, 이미 생성된 쓰레드가 가용하다면 이를 먼저 재사용한다.
- 주로 생명주기가 짧은 비동기 작업들을 많을 때 사용하면 성능을 향상시킬 수 있다고 한다.
- newSingleThreadExecutor
- 쓰레드 한 개만 가지는 쓰레드 풀을 생성한다.
- 무제한 작업 큐에서 동작한다
상황에 맞는 적절한 팩토리 메서드를 호출하여 사용하면 된다. 뒤에서 다루겠지만 자바 7부터 좀 더 병렬처리에 특화된 work-stealing 알고리즘을 사용하는 ExecutorService의 구현체, ForkJoinPool객체가 등장한다. 그리고 자바 8부터 Executors에서 이를 생성하기 위한 팩토리 메서드 - Executors.newWorkStealingPool() - 를 제공한다.
사용 예시
다음은 숫자 1~ 1000 까지의 숫자를 더하는 예제를 통해 쓰레드 풀을 사용했을 때와 아닐 때를 비교해볼 것이다.
먼저 첫 번째 코드는 단순 반복문으로 순차적으로 숫자들을 더하는 코드이고, 두 번째 코드는 ExecutorService를 이용하여 10개의 쓰레드를 생성하여 운영하는 쓰레드 풀을 사용해 병렬로 처리하는 코드이다.
여기서 눈여겨 봐야할 부분은 숫자들을 더할 때마다 10밀리세컨드의 지연 - Thread.sleep(10) - 을 준 부분이다. 예시에서 사용하는 더하기 연산은 간단한 연산으로 처리 속도가 매우 빠르다. 만약 시간 지연을 주지않으면 병렬처리시 스레드 생성, 스케줄링 시간 등의 오버헤드 시간이 작업시간보다 오래 걸리기 때문에 순차로 처리하는 것이 더 빠를 것이다. 하기에 병렬처리 하기에 적절한 환경(쓰레드 생성 비용보다 작업 처리 비용이 큰 상황)을 만들고자 의도적으로 연산 시간을 최소 10밀리세컨드가 되도록 설정했다.
실험 환경을 만들고자 조건을 준 것이니, 실제로는 스레드를 나눠서 데이터를 처리하는 과정에서 발생하는 데이터 이동하는 시간과 기타 오버헤드로 발생하는 추가 비용을 상쇄할만큼의 효과가 있는지 따져서 병렬 처리를 진행해야 한다.
1. 순차처리 코드
@Test
void sequential_process_when_simple_sequential_iteration() throws InterruptedException {
long start = System.nanoTime();
int totalResult = 0;
for (int number = 0; number <= 1000; number++) {
totalResult += number;
Thread.sleep(10);
}
// 결과 출력
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("sequential iteration = total : %s, timespent: %s msecs%n", totalResult, duration);
}
2. 병렬처리 코드
@Test
void parallel_process_when_ExecutorService_is_fixedSizePool() throws InterruptedException, ExecutionException {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
ExecutorService executor = Executors.newFixedThreadPool(10);
long start = System.nanoTime();
int totalResult = 0;
// parallel : multi-threading
List<Future<Integer>> results = new ArrayList<>();
for (List<Integer> numbers : targetNumbers) {
// chunk단위로 숫자합을 계산하는 작업 제출
results.add(executor.submit(new SimpleNumberChunkCalculation(numbers)));
}
for (Future<Integer> result : results) {
totalResult += result.get(); // 비동기 작업의 결과를 가져오는 부분
Thread.sleep(10);
}
executor.shutdownNow(); // 이미 제출된 작업들을 인터럽트&종료
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel1 = total : %s, timespent: %s msecs%n", totalResult, duration);
}public class SimpleNumberChunkCalculation implements Callable<Integer> {
private final List<Integer> numbers;
public SimpleNumberChunkCalculation(List<Integer> numbers) {
this.numbers = numbers;
}
@Override
public Integer call() {
return sum();
}
public Integer sum() {
Integer sum = 0;
for (Integer num : numbers) { // NOTE: Due to the experimentation with versions prior to Java8, steam api is not used.
sum += num;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
return sum;
}
}
결과

더하기 연산이 10 밀리초가 걸린다는 가정하에 쓰레드 10개로 운영되는 쓰레드 풀을 사용했더니 약 10배 정도의 속도차이가 난다. 스레드 풀을 잘 활용하면 더 빠른 시간내에 작업을 마무리할 수 있다.
Java 8 이후
stream 의 parallel() - 병렬 스트림
Java8이 들어서면서 stream API가 등장했다. stream API에서는 stream이 병렬 실행될 수 있도록 parallel() 기능을 제공한다. 컬렉션에서도 일반 stream이 아닌 병렬 스트림을 사용하고 싶다면 .stream()이 아닌 .parallelStream()을 호출해서 사용하면 된다.
ForkJoinPool
앞서서 언급한 것과 같이 java7부터 ExecutorService의 구현체로 ForkJoinPool이 추가되었다. parallel()로 병렬 스트림을 사용한다면, 쓰레드 풀로 ForkJoinPool을 사용한다. ForkJoinPool의 특징은 분할/정복 기법과 work stealing 기법을 적용해 병렬 처리를 지원한다는 것이다.
ForkJoinPool은 재귀적으로 병렬처리할 작업을 작은 작업으로 분할한 다음, 더 이상 작업을 분할할 수 없을 때 쪼갠 작업들을 합쳐서 전체 결과를 만들고 work stealing(작업훔치기) 기법을 통해 스레드가 작업을 효율적으로 처리할 수 있게 한다. work stealing 알고리즘은 작업이 끝난 스레드를 유휴상태(idle)로 두지 않고 다른 스레드에 대기중인 작업(링크드리스트의 꼬리 부분)을 가져와 처리하여 CPU를 효율적을 사용하는 기법을 말한다.
ForkJoinPool가 동작하는 방식은 다음과 같다. 참고로 분할 작업은 작업을 더 이상 나눌 수 없을 때까지 재귀적으로 진행되며, 쪼개진 subtask들이 모두 완료되면 쪼개진 곳에서 합쳐져서 반한된다. (Conquer - join)
- 작업을 Fork를 통해 subtask로 분할 (Divide).
- 분할된 작업들을 global shared queue에 submit.
- global shared queue에 있는 작업들이 ForkJoinPool에 할당된 쓰레드들로 분배.
- 쓰레드 각각 작업 진행
- 만약 어떤 쓰레드(A)가 자신에게 할당된 모든 일을 다 처리했거나 할일이 없으면, work-stealling가 동작하여 다른 쓰레드 큐에서 남은 작업을 가져와 처리 (이 부분에서 성능 최적화)
- 작업을 주는 쓰레드는 작업을 훔치는 쓰레드에게 어떤 작업을 훔쳐가면되는지 알려주고, 마땅한게 없을 경우 Fail메시지를 보냄.
- 상황에 따라 작업을 끝낸 쓰레드(A)는 작업 다른 쓰레드에서 업무를 훔칠지 global shared queue에서 가져올지 결정
(참고 : ForkJoinPool이 어떻게 동작하는지 자세히 알고 싶다면. 해당 블로그들을 참고 하도록 하자.
ForkJoinPool - https://theboreddev.com/discover-java-forkjoinpool/ ,
paralle steam ForkJoinPool - https://stackabuse.com/java-8-streams-guide-to-parallel-streaming-with-parallel/)
사용 예시
다음은 병렬스트림을 사용하여 숫자 합을 구하는 예시이다.
병렬스트림을 사용할경우 몇 가지 주의 사항이 있다.
- 자동 박싱과 언박싱 비용이 크기 때문에 조심하자. 가령, int연산을 Integer로 바꾸다던지, Integer를 int로 바꾸는 지점은 없는지 확인하자.
- ForkJoinPool은 애플리케이션 내에서 공유된다. 동시에 여러군데서 parallelStream을 남용할 경우 성능이 저하될 수 있다.
-> ForkJoinPool의 디폴트 스레드 개수는 Runtime.getRuntime().availableProcessors()이를 반환하는 값과 관련있다.
@Test
void parallel_process_with_parallel_stream() {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
long start = System.nanoTime();
// parallel stream
int totalResult = targetNumbers.stream()
.parallel()
.mapToInt(number -> {
try {
Thread.sleep(10); // subTask 끼리 합할 때 10초 delay
return new SimpleNumberChunkCalculation(number).sum();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
})
.sum();
// 결과 출력
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel2 = total : %s, timespent: %s msecs%n", totalResult, duration);
}

더하기 연산에 10초 지연을 주기 위해 위와 같은 코드를 작성했지만, 10초 지연을 주지않는다면 다음과 같이 코드와 실행속도가 짧아질 수 있다.
@Test
void parallel_process_with_not_delayed_parallel_stream() {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
long start = System.nanoTime();
// parallel stream
int totalResult = targetNumbers.stream()
.parallel()
.mapToInt(subNumbers -> subNumbers.stream().reduce(0, Integer::sum))
.sum();
// 결과 출력
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel2 no delay = total : %s, timespent: %s msecs%n", totalResult, duration);
}
CompletableFuture (feat. Future)
java9에서는 CompletableFuture가 등장했다. CompleatableFuture는 Future의 구현체 중 하나이다. CompleatableFuture는 기존 Future 인터페이스 메서드 외에도 다양한 메서드를 제공한다. 그리고 여러 Future 결과들에 대한 의존성을 표현할 수 있는 유용한 기능들을 선언형으로 사용할 수 있고, stream 처럼 람다 표현식과 파이프라이닝을 활용할 수 있다.
(참고 : Modern Java In Action에서는 Future와 CompletableFuture의 관계를 Collection과 Stream으로 비유한다.)
사용예시
다음은 CompletableFuture와 Future를 사용했을 때의 코드이다. CompletableFuture를 쓰는 것이 좀 더 선언적이고 가독성이 높다.
/* CompletableFuture를 사용한 병렬처리 */
@Test
void parallel_process_with_CompletableFuture() {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
long start = System.nanoTime();
List<CompletableFuture<Integer>> chunkResult = targetNumbers.stream()
.map(numbers -> CompletableFuture.supplyAsync( // 비동기로 처리
() -> new SimpleNumberChunkCalculation(numbers).sum()
))
.toList();
Integer totalResult = chunkResult.stream()
.map(CompletableFuture::join) // 모든 비동기 작업이 끝나길 기다려 합산
.reduce(0, Integer::sum);
// 결과 출력
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("number of Threads : %s\n", Runtime.getRuntime().availableProcessors());
System.out.printf("number of genuinely used Threads : %s\n", ForkJoinPool.getCommonPoolParallelism()); // 디폴트 쓰레드의 개수
System.out.printf("parallel3 = total : %s, timespent: %s msecs%n", totalResult, duration);
}
/* Future를 사용한 병렬처리 */
@Test
void parallel_process_with_Future() throws InterruptedException, ExecutionException {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
ExecutorService executor = Executors.newFixedThreadPool(10);
long start = System.nanoTime();
int totalResult = 0;
// parallel : multi-threading
List<Future<Integer>> results = new ArrayList<>();
for (List<Integer> numbers : targetNumbers) {
results.add(executor.submit(new SimpleNumberChunkCalculation(numbers)));
}
for (Future<Integer> result : results) {
totalResult += result.get(); // 비동기 작업의 결과를 가져오는 부분
Thread.sleep(10);
}
executor.shutdownNow(); // 이미 제출된 작업들을 인터럽트&종료
// 결과 출력
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel1 = total : %s, timespent: %s msecs%n", totalResult, duration);
}
그런데 CompletableFuture의 결과를 보면 Future를 사용했을 때(1350ms)보다 약 2배가 더 걸린다.

결과 출력에서 예측했듯이 9개의 스레드를 사용하고 있다. CompletableFuture는 ForkJoinPool의 common pool을 디폴트로 사용용한다. ForkJoinPool.getCommonPoolParallelism()을 하면 common pool이 몇 개의 쓰레드를 생성하여 사용하는지 알 수 있는데, 여기서는 그 개수가 9개인 것이다. 따라서 9개의 스레드로 10개의 숫자 청크를 처리했기 때문에 최대 9개가 청크가 동시에 처리되고, 나머지 한 개의 청크가 작업이 끝난 스레드로 처리하기 때문에 예상한 시간보다 2배가 걸린 것이다. 이에 10개의 쓰레드가 동시에 처리할 수 있도록 Executor를 커스터마이즈하여 생성한 뒤 supplyAsync의 두 번째 인자로 넘겨주면 시간을 단축시킬 수 있다.
private final Executor executor = Executors.newFixedThreadPool(10, r -> { // 쓰레드 10개 생성
Thread t = new Thread(r);
t.setDaemon(true);
return t;
});
@Test
void parallel_process_with_CompletableFuture() {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
long start = System.nanoTime();
List<CompletableFuture<Integer>> chunkResult = targetNumbers.stream()
.map(numbers -> CompletableFuture.supplyAsync( // 비동기로 처리
() -> new SimpleNumberChunkCalculation(numbers).sum(),
executor // executor를 넘겨주지 않으면 ForkJoinPool.getCommonPoolParallelism()의 수만큼 쓰레드 사용
))
.toList();
...
Reactive Programming 방법 - WebFlux, Reactor
마지막으로 소개할 Java에서 비동기로 여러 작업을 처리하는 방법은 리액티브 프로그래밍 방법이다. Reactor(Project Reactor)를 사용하는 방법과 최근에(?) 여러곳에서 도입하고 있는 Spring WebFlux 프레임워크를 사용하는 방법을 알아볼 것이다.
Reactor, WebFlux
Reactor는 리액티브 프로그래밍을 구현하는 Java 라이브러리이다. Reactor는 리액티브 스트림(Reactive Streams)스펙을 기반으로 만들어졌으며, 비동기 및 이벤트 기반 애플리케이션을 개발하기 위한 도구로 사용된다.
한편, Spring WebFlux는 Spring 5.0부터 추가된 스프링 프레임워크의 모듈 중 하나로, 리액티브 웹 애플리케이션을 구현하기 위한 웹 프레임워크이다. WebFlux는 Reactor를 사용하여 리액티브 프로그래밍을 지원한다. 현재까지도 가장 많이 사용되고 있는 Spring MVC 프레임워크와 비교해보자면, Spring MVC는 하나의 요청을 처리하기 위해 하나의 스레드를 사용하고 요청이 끝날 때까지 스레드를 차단하는 blocking I/O 방식의 프레임워크인 반면, Spring WebFlux는 비동기 non-blocking I/O 방식으로 적은 수의 스레드로 대량의 요청을 안정적으로 처리할 수 있게 한다.
따라서 Reactor, Spring WebFlux 둘 다 리액티브 프로그래밍을 위한 것이지만, Reactor는 일반적인 리액티브 애플리케이션의 개발에 사용되는 반면, Spring WebFlux는 웹 애플리케이션의 경우에 특화되어 있다.
만약 위 예시의 연산 기능이 모듈로 분리되어 마이크로 서비스에 API 요청을 해야한다면, Spring WebFlux 프레임워크와 이에 상응하는 요청 클라이언트 WebClient를 사용하면 동시 요청을 적은 쓰레드로 빠르게 처리할 수 있다. 이러한 경우를 살펴보기 위해 Reactor뿐만 아니라 Spring WebFlux도 함께 살펴보려고 한다.
예시를 보기에 앞서서 새롭게 등장한 개념, 리액티브 프로그래밍과 리액티브 스트림에 대해 정리하고 간다.
리액티브 프로그래밍
리액티브 프로그래밍은 리액티브 시스템을 구축하기 위한 프로그래밍 모델이다. 그리고 리액티브 시스템이란 클라이언트 요청에 즉각적으로 응답하여 지연시간을 최소화하는 시스템을 말한다. 시간이 지나면서 기하급수적으로 증가하는 대용량 데이터를 사용자에게 빠르게 응답하기 위해 리액티브 프로그래밍 패러다임의 중요해졌고, 이에 리액티브 시스템을 위한 기법이 등장한 것이다.
리액티브 메니페스트
리액티브 시스템 설계의 지향점을 적절하게 실현할 수 있도록 리액티브 메니페스토(Reactive Manifesto)라는 문서에 리액티브 시스템의 설계 원칙과 목표를 정의하였다.
리액티브 메니페스트에 서술된 네 가지 리액티브 시스템의 핵심 원칙은 다음과 같다.
- Responsive (응답성)
시스템은 항상 사용자의 요청 또는 외부 이벤트에 신속하게 응답해야 한다. 이를 위해는 빠른 응답 시간과 일관된 성능이 보장되어야 한다. - Resilient (회복성)
시스템은 장애를 견디고 회복할 수 있어야 한다. 즉, 부분적인 실패가 발생해도 시스템이 계속해서 응답성을 일정하게 유지되어야 한다. - Elastic (탄력성)
시스템은 작업량이 변화해도 일정한 응답을 유지해야 한다. 즉, 부하가 증가하면 자원을 동적으로 확장하고, 부하가 감소하면 자원을 축소하여 탄력적이고 효율적으로 자원을 활용해야 한다. - Message-Driven (메시지 기반)
시스템은 비동기적이고 이벤트 기반의 통신을 사용하여 컴포넌트 간의 상호 작용을 수행해야 한다. 이를 통해 느슨한 결합을 유지하고, 확장성과 유연성을 높일 수 있다.
리액티브 스트림
그렇다면 리액티브 메니페스토에 따르는 리액티브 프로그래밍 모델을 어떻게 구현할 수 있을까? 이를 지원하기 위해 리액티브 스트림(Reative Streams)라고 표준 사양이 등장했다. 리액티브 스트림을 구현한 구현체로는 Java 9 Flow API, RxJava, Reactor, Akka Stream 등이 있고, 개발자의 리액티브 프로그래밍을 지원한다.
- 리액티브 프로그래밍 : 리액티브 스트림을 사용하는 프로그래밍
- 리태티브 스트림 : 무한의 비동기 데이터를 역압력을 바탕으로 처리하는 표준 기술
- 역압력 : publish/subscribe 프로토콜에서 subscriber가 publisher가 이벤트를 제공하는 속도보다 느리게 이벤트를 소비하는 개념으로 안전하게 이벤트를 소비할 수 있게 보장하는 장치
- 리액티브 스트림의 핵심 요소 : publisher, subscriber, subscription, processor
여기서 Reactor는 Spring Framework 팀이 주도적으로 개발한 구현체로, 바로 다음 예시에서 Reactor를 사용해 비동기로 처리해 볼 것이다.
사용예시
1. Reactor
먼저 10개의 청크를 병렬로 처리하기 위해서, Flux.fromInterable로 청크들을 데이터스트림으로 만드는 Flux 타입의 publisher를 만든다. 각 청크들은 .parallel()을 통해 병렬로 처리되며 flapMap 연산을 통해 합을 구한다. 연산의 결과인 값 하나 필요하기 때문에 이 때는 Mono타입의 퍼블리셔를 사용한다.
또한 CountDownLatch의 초기 값을 10개를 주고, 숫자 청크의 연산결과를 더했으면 CountDown을 하도록 했다. latch.await()으로 작업들을 기다리던 중 마지막 작업이 완료되는 순간 count가 0이되고 대기상태가 해제된다.
- Flux : 0부터 여러 개의 데이터를 발생. 다수의 값을 가질 수 있으며, 데이터의 흐름이 여러 개일 때 사용한다.
- Mono : 0 또는 1개의 데이터를 발생. 단일 값을 가질 수 있어, 주로 단일 결과를 처리할 때 사용한다
- CountDouwnLatch : 한 쓰레드가 다른 쓰레드에서 작업이 완료될 때까지 기다릴 수 있도록 해주는 클래스
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
@Test
void parallel_process_with_reactor() throws InterruptedException {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
CountDownLatch latch = new CountDownLatch(10); // 동시에 처리할 작업이 10개
AtomicInteger totalResult = new AtomicInteger(0);
long start = System.nanoTime();
Flux.fromIterable(targetNumbers)
.parallel() // 병렬 처리 시작
.runOn(Schedulers.parallel()) // 병렬 실행을 위한 스케줄러 설정
.flatMap(chunkNumbers ->
Mono.fromCallable(() -> new SimpleNumberChunkCalculation(chunkNumbers).sum())
)
.subscribe(
totalResult::addAndGet,
error -> {
System.err.println("Error occurred: " + error);
latch.countDown();
},
latch::countDown
);
// 모든 작업의 결과를 기다림
latch.await();
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel4 = total : %s, timespent: %s msecs%n", totalResult, duration);
}
2. WebFlux
합을 구하는 기능을 API만들어서 Spring WebFlux의 WebClient로 요청해서 합산하도록 변경했다. 더불어 WebClient의 코드를 RestTempalate을 사용하는 코드로 바꿔봤는데, WebClient를 썼을 때 코드가 선언적이며 가독성이 올라간 것을 느낄 수 있다.
<WebClient>
@Test
void parallel_process_with_webFlux() throws InterruptedException {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
CountDownLatch latch = new CountDownLatch(10); // 동시에 처리할 작업이 10개이므로
AtomicInteger totalResult = new AtomicInteger(0);
long start = System.nanoTime();
Flux.fromIterable(targetNumbers)
.parallel() // 병렬 처리 시작
.runOn(Schedulers.parallel()) // 병렬 실행을 위한 스케줄러 설정
.flatMap(chunkNumbers ->
// WebClient를 사용하여 REST API 요청 보내고 결과를 받아오는 Mono 생성 - 비동기 요청
WebClient.create("http://localhost:8080")
.post()
.uri("/v1/sum")
.contentType(MediaType.APPLICATION_JSON)
.bodyValue(chunkNumbers)
.retrieve()
.bodyToMono(Integer.class)
)
.subscribe(
totalResult::addAndGet,
error -> {
System.err.println("Error occurred: " + error);
latch.countDown();
},
latch::countDown
);
// 모든 작업의 결과를 기다림
latch.await();
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel4 with webFlux = total : %s, timespent: %s msecs%n", totalResult, duration);
}
<RestTemplate>
@Test
void parallel_process_with_blocking_client() throws InterruptedException {
List<List<Integer>> targetNumbers = StubNumbers.getNumbers();
CountDownLatch latch = new CountDownLatch(10);
AtomicInteger totalResult = new AtomicInteger(0);
long start = System.nanoTime();
RestTemplate restTemplate = new RestTemplate();
Flux.fromIterable(targetNumbers)
.parallel() // 병렬 처리 시작
.runOn(Schedulers.parallel()) // 병렬 실행을 위한 스케줄러 설정
.flatMap(chunkNumbers -> {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<List<Integer>> requestEntity = new HttpEntity<>(chunkNumbers, headers);
ResponseEntity<Integer> responseEntity = restTemplate.postForEntity(
"http://localhost:8080/v1/sum",
requestEntity,
Integer.class
);
totalResult.addAndGet(responseEntity.getBody());
latch.countDown();
return Flux.empty(); // 빈 Flux 반환
})
.subscribe(); // 구독
// 모든 작업의 결과를 기다림
latch.await();
long duration = (System.nanoTime() - start) / 1000000;
System.out.printf("parallel4 with restTemplate = total : %s, timespent: %s msecs%n", totalResult, duration);
}
결과
<chunk 단위가 100일 때>


<chunk 단위가 1000일 때>


그런데 결과를 보면.. 이게 왠일인가! 청크 단위가 100로 1~1000까지 더하는 연산에서 WebFlux의 WebClient를 사용했을 때 다른 병렬처리보다 2~3배 정도 더 걸리고, RestTemplate을 사용했을 때 1~2배 정도 걸린다.
그래서 청크 단위를 1000으로 늘려 1~10000까지 더하는 연산을 해봤다. RestTemplate은 다른 병렬처리와 비슷한 성능을, WebClient는 2초정도 차이난다.
(참고 : 일반적으로는 WebClient가 RestTemplate보다 성능이 좋다고 한다.)
아무래도 WebClient나 RestTemplate는 API요청을 처리하는 것이다보니 네트워크로 인한 비용이 발생할 수 밖에 없고, 특히나 데이터가 많지 않다면 크게 성능향상에 효과를 보기 어려울 것이라고 생각한다.
마무리
Java 버전에 따라 병렬처리를 어떻게 다루는지 알아보았다. 쓰레드를 잘 조절해서 방대한 작업을 병렬처리한다면 성능향상을 꾀할 수 있다. 그러나 모든 경우가 멀티쓰레드로 병렬처리했을 때 성능이 좋아지는 것은 아니다. 순차처리 하는 것보다 더 느려질 수도 있다.
> 멀티쓰레드로 인해 발생하는 추가 비용을 상쇄할만큼의 효과가 있는지를 따져보고 측정해서 성능을 향상시키자.
> 병렬처리를 할 경우 자료구조로 인해 예상치 못한 성능 저하가 생기기도 한다. 박싱과 언박싱, 스트림구성을 확인하자.
여기서 작성한 코드들을 전부 보려면 여기로 이동 ⬇️
https://github.com/jihyunhillpark/java-practice
(+ 전에 Kotlin에서 코루틴을 사용하여 병렬&비동기로 요청을 하는 코드를 본 적이 있는데, 나중에 코틀린을 스터디 한다면 코루틴을 사용한 방식과 비교해봐도 재밌을 것 같다.)
참고
- 모던 자바 인 액션 edition2.
- https://mangkyu.tistory.com/259
- https://mangkyu.tistory.com/263
- https://www.baeldung.com/java-future
- https://theserverside.tistory.com/1823
- https://rudaks.tistory.com/entry/%EC%9E%90%EB%B0%94%EC%9D%98-%EC%93%B0%EB%A0%88%EB%93%9C-%ED%92%80-ExecutorService
- https://findmypiece.tistory.com/174
- https://www.logicbig.com/tutorials/core-java-tutorial/java-multi-threading/fork-and-join.html
- https://therealsainath.medium.com/resttemplate-vs-webclient-vs-httpclient-a-comprehensive-comparison-69a378c2695b
'개발노트 > Spring | Java' 카테고리의 다른 글
| Spring Boot에서 Robots.txt를 추가했는데 왜 적용이 안될까? (feat. 스프링 MVC 자동구성) (0) | 2024.02.18 |
|---|---|
| 자바 Heap 메모리 관리 - GC.Garbage Collection (feat. 서비스를 살려야한다!) (1) | 2024.02.04 |
| AOP - Spring에서 AOP기술을 어떻게 쓸까? (0) | 2023.12.30 |
| (Spring)JUnit5 - 테스트코드 작성을 지원하는 프레임워크 (0) | 2023.12.10 |
| Java 멀티 스레딩 (0) | 2023.06.06 |



